[AWS교육]비즈니스 관점에서 RAG의 이해
2024. 5. 28. 10:51ㆍAI
728x90
반응형
(참고) RAG의 기본개념
RAG는 "Retrieval-Augmented Generation"의 약자로, 텍스트 생성 모델의 성능을 향상시키기 위해 검색(retrieval) 기술을 결합한 접근 방식입니다. RAG는 크게 두 가지 주요 컴포넌트로 구성됩니다:
RAG의 작동 원리
RAG의 장점
사용 사례
|
(RAG의 비즈니스적 이해)
ㆍRAG
- 질의응답 X
- 정답이 포함된 문서를 찾는 기술 O

embeding : semantic의미 있는 array의 형태로 저장되는
embeding값과의 유사성이 있는 대상을 추출.
1.
* semantic은 물론이고 lexical도 포함되어야함.




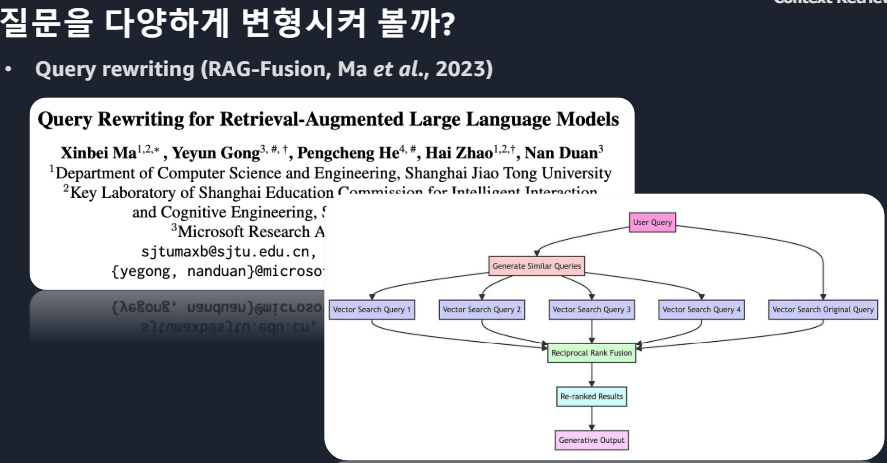


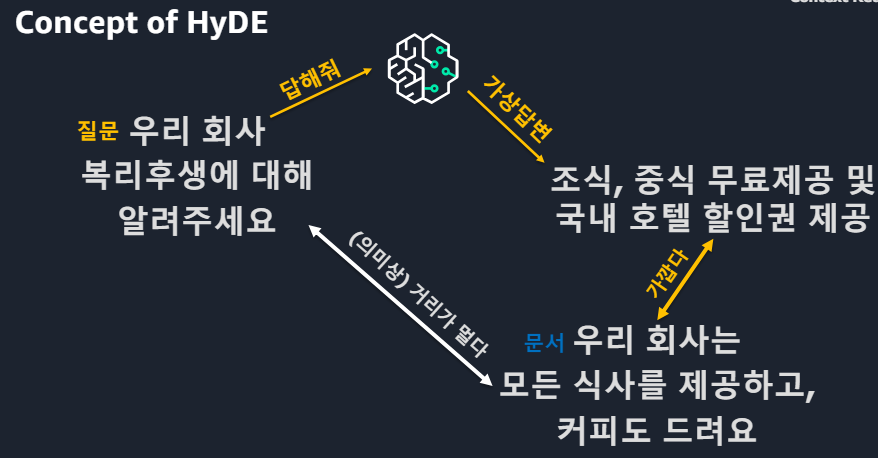
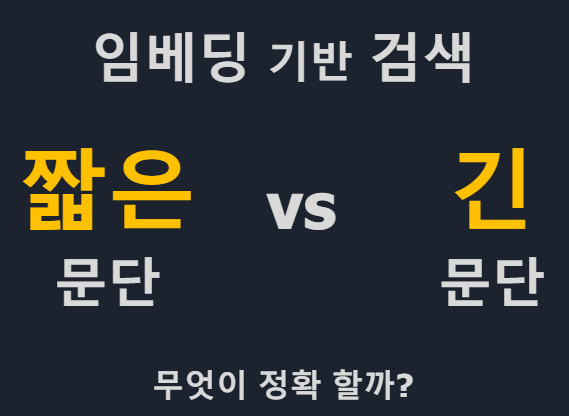
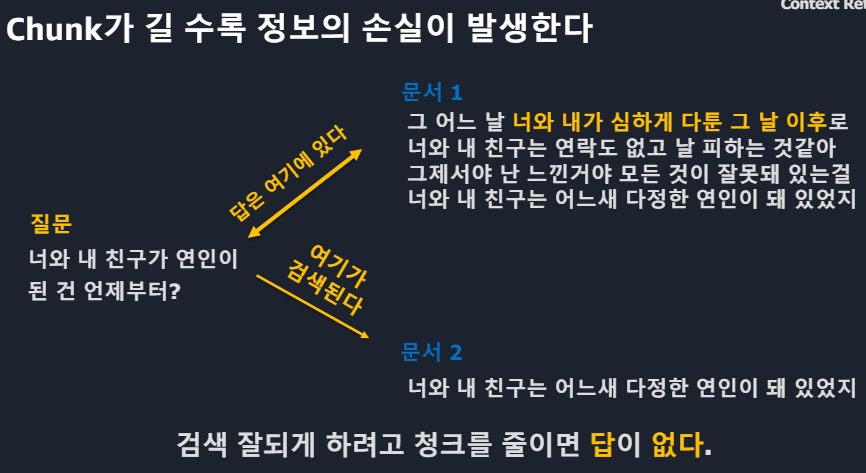
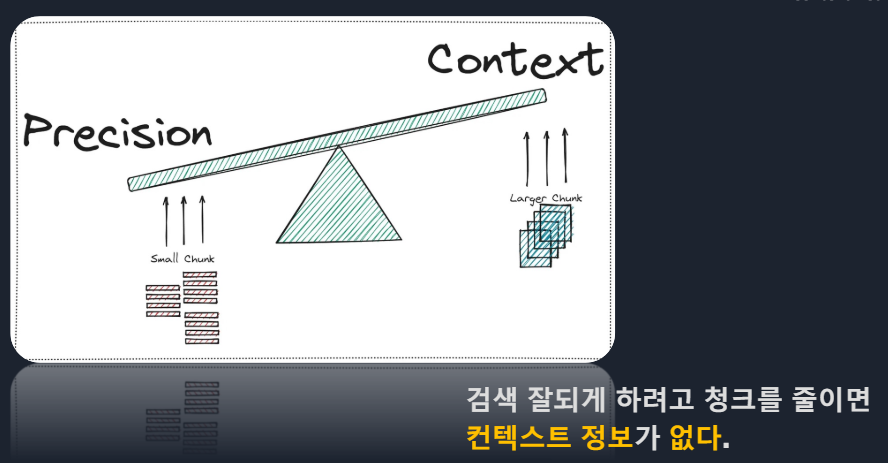
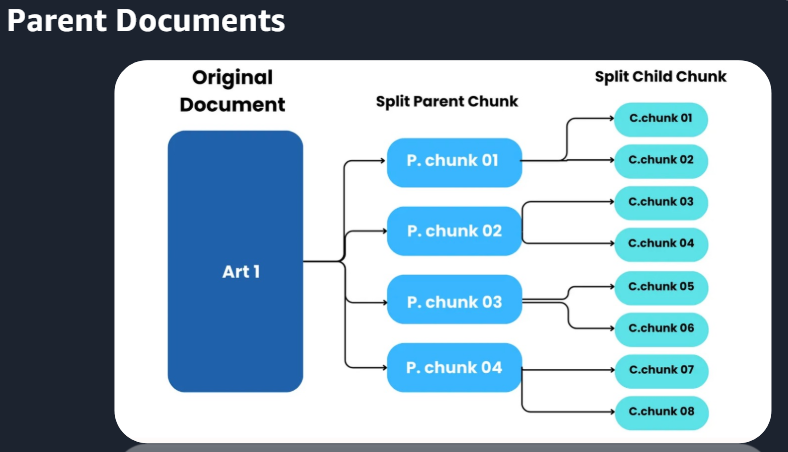
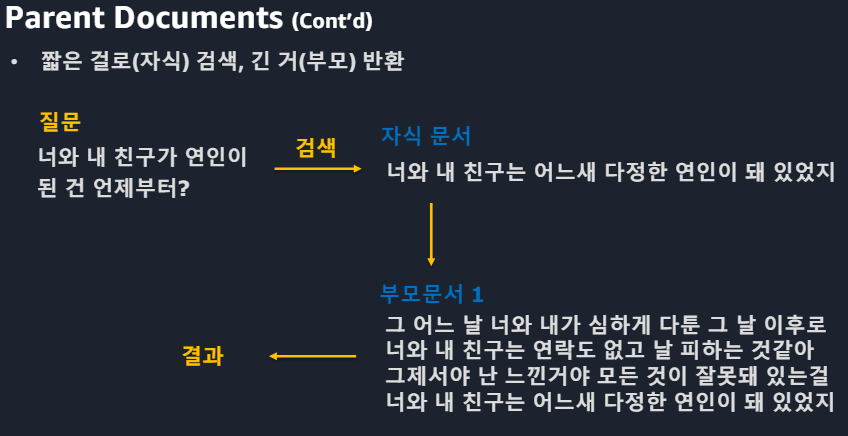




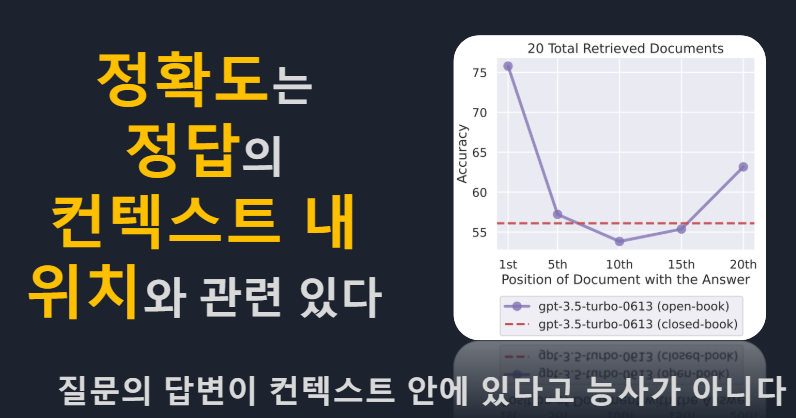

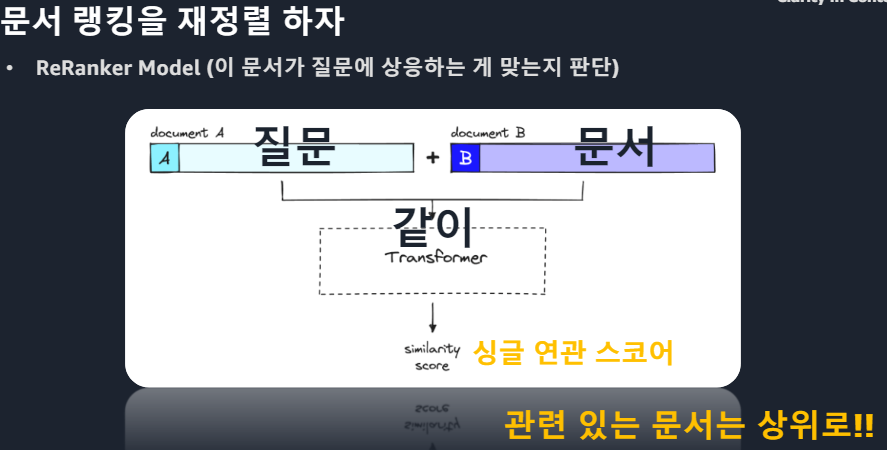
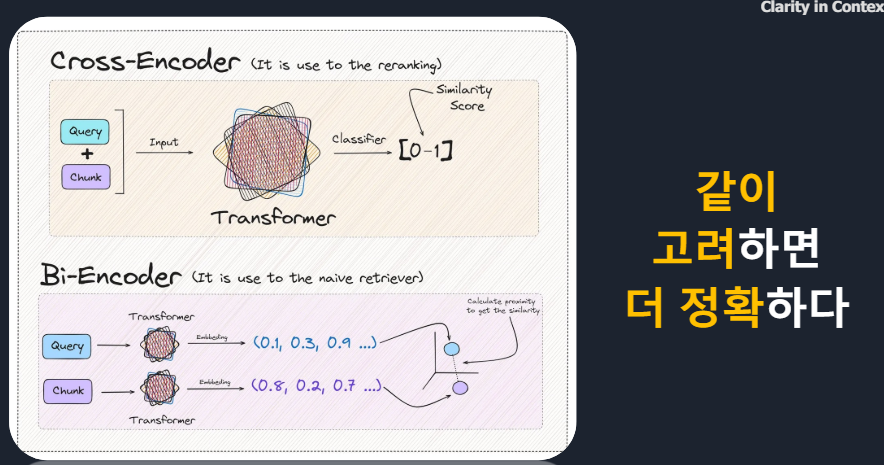
*Cross-Encoder 단점 : 모든 대상을 계산해야해서 오래걸린다
* Bi-Encoder 장점 : 빠르다
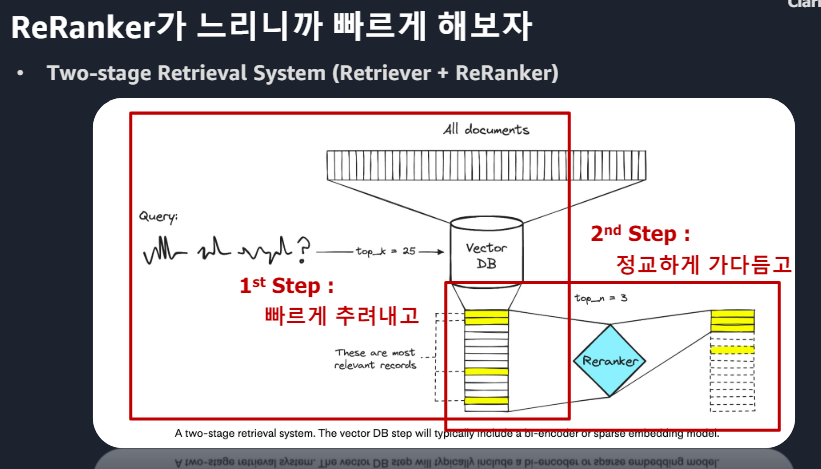




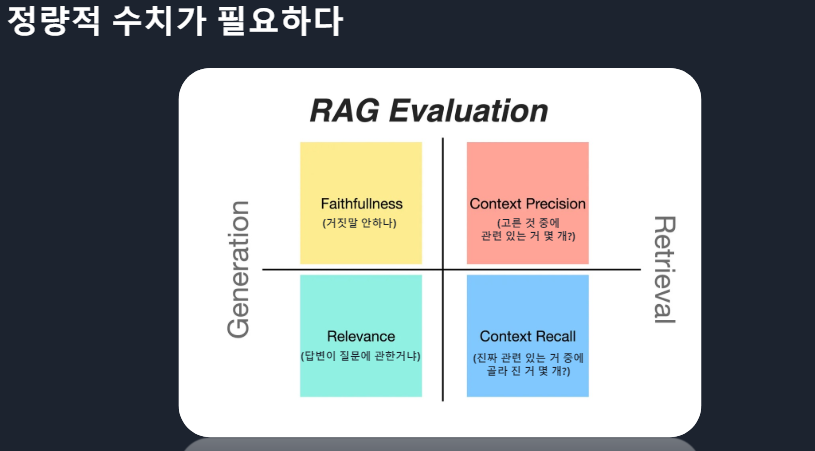
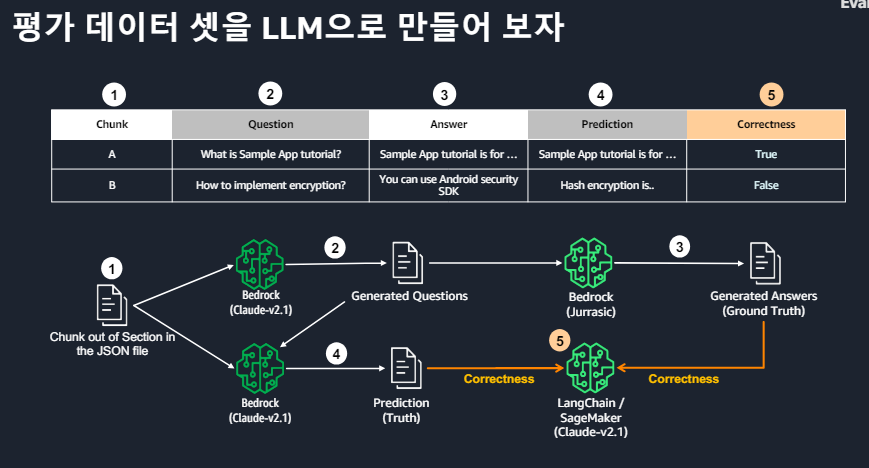
ㆍwrap up

728x90
반응형
'AI' 카테고리의 다른 글
| [정보]AICE 인공지능 능력시험 (접수기간 ~ 7.6) (1) | 2024.06.24 |
|---|---|
| [NLP모델학습]BERT모델 경량화 방식 비교 (0) | 2024.06.24 |
| [AWS]비즈니스 관점에서 파인튜닝 이해 (0) | 2024.06.11 |