2021. 3. 25. 22:24ㆍ컴퓨터과학
3번 Cell) 필요한 칼럼만 추려서 저장하기
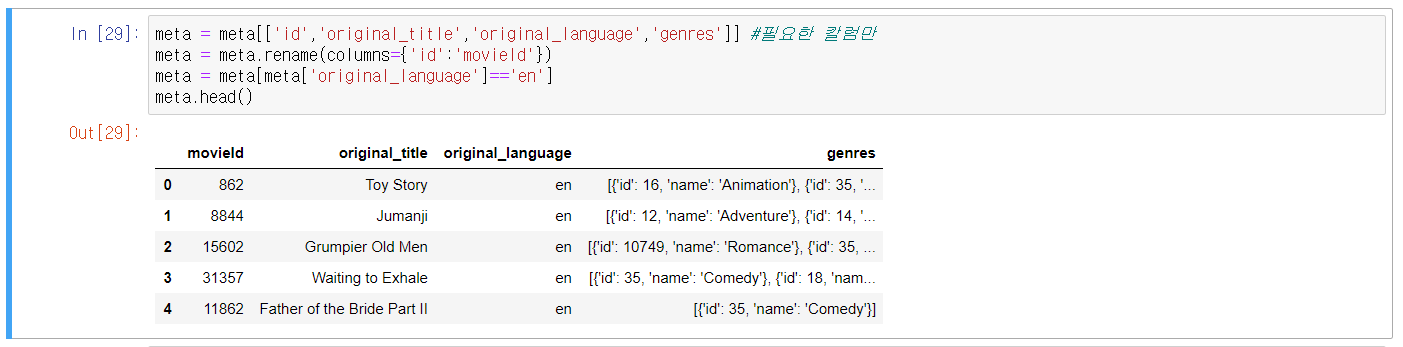
ㆍ1줄) meta에 불러온 csv파일에서 필요한 칼럼만 추려서 다시 meta에 저장.
ㆍ2줄) id칼럼의 이름을 movieId로 변경하여 저장
ㆍ3줄) original_language가 en로 되어있는 영화만 추려서 다시 meta에 저장.
4번 Cell) 평가정보 csv파일 불러오고 필요한 칼럼만 추려서 저장하기
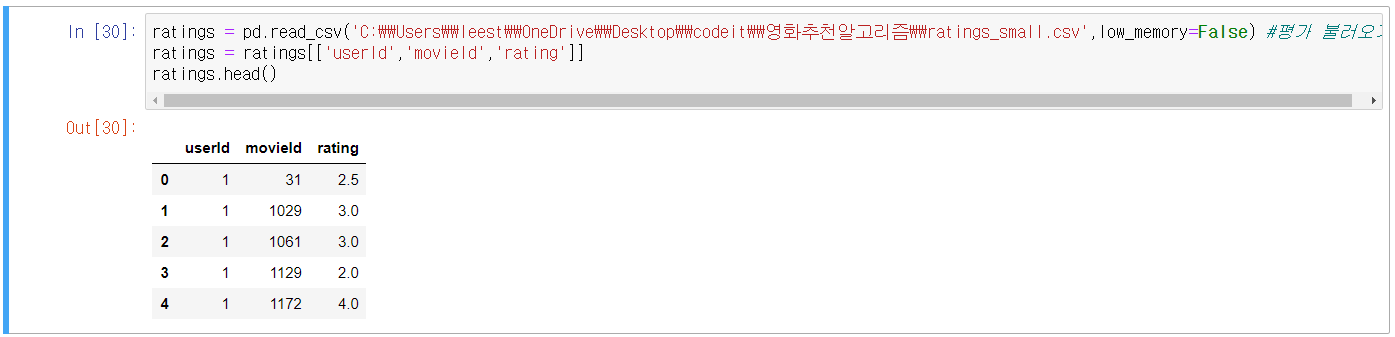
ㆍ2줄) ratings에 불러온 csv파일에서 필요한 칼럼만 추려서 다시 meta에 저장.
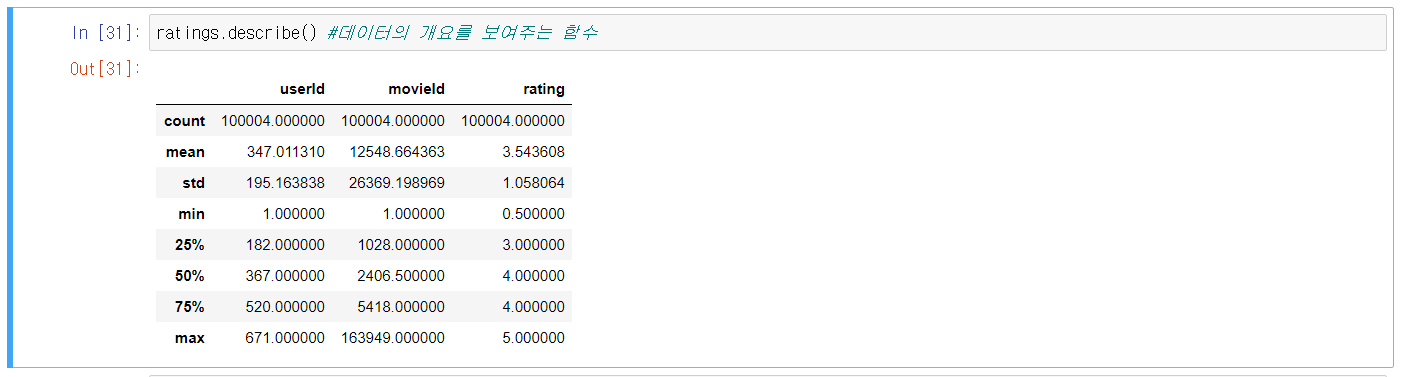
5번 Cell) ratings에 저장된 테이블 데이터의 개요를 확인
6, 7번 Cell) movieId를 숫자형식으로 변환, genres를 보기 편하게 변환
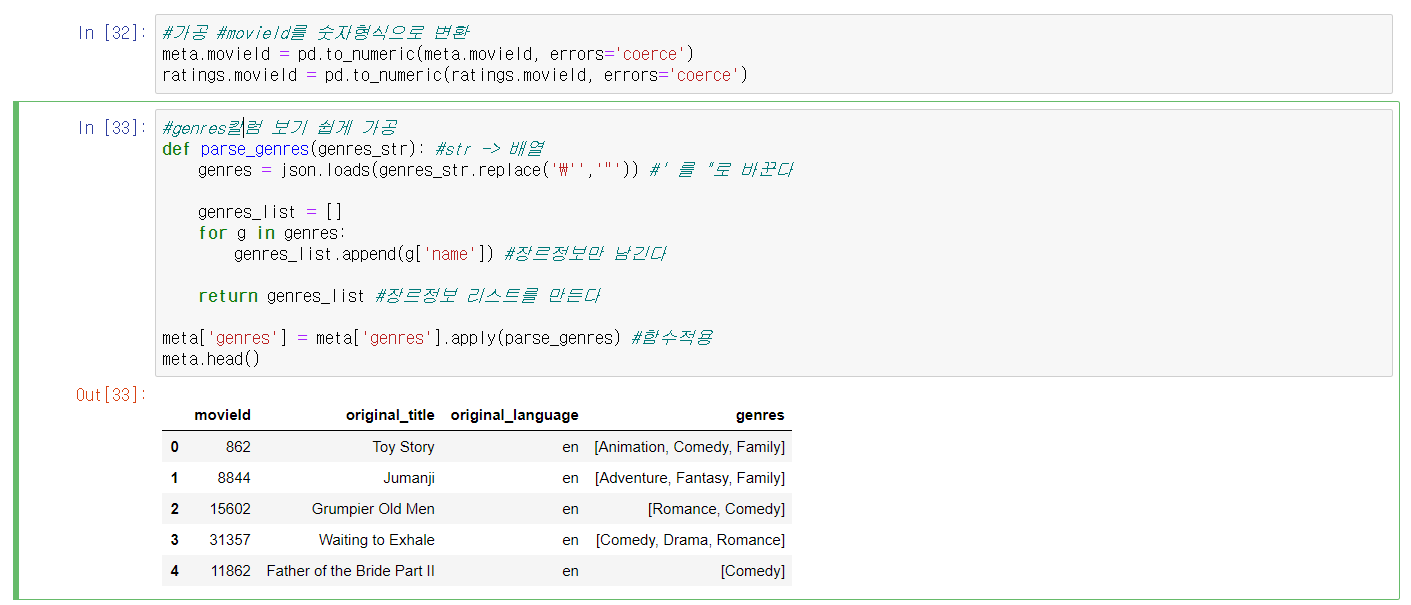
ㆍ6번 Cell) 문자열 형식인 movieId를 숫자형식으로 변환한다.
- errors = 'coerce' : 숫자만으로 이루어지지 않고 문자가 포함되어 있는 경우에 ValueError를 무시하고 강제로 'NaN'으 값으로 변환한다.
ㆍ7번 Cell) 지저분한 genres칼럼의 내용을 정리하여 저장한다.
- parse_genres()함수를 정의하고 meta['genres']에 적용하는 apply함수를 사용한다.
출처: https://rfriend.tistory.com/470 [R, Python 분석과 프로그래밍의 친구 (by R Friend)]
8번 Cell) Meta와 Ratings 테이블을 합친다.(Join한다)
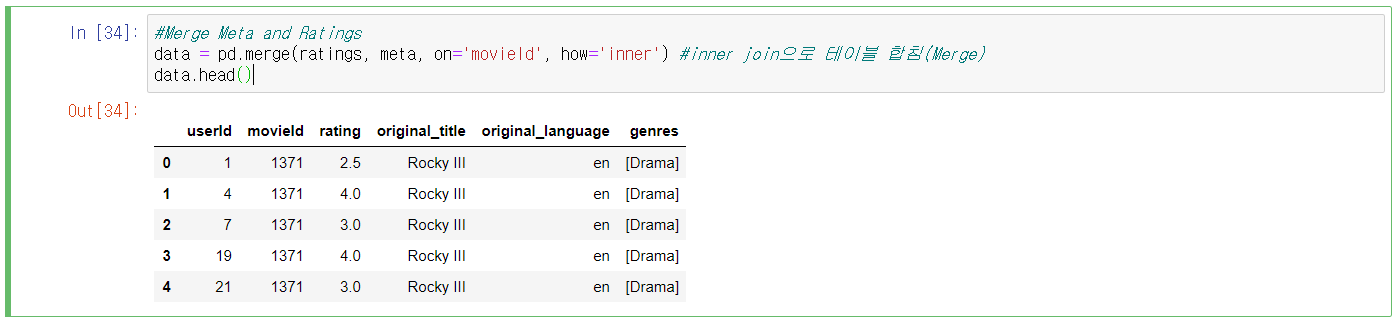
ㆍ1줄) movieId를 기준으로 하여 Inner Join한 테이블을 data에 저장한다.
- Join : 한 데이터베이스 내의 여러 테이블의 레코드를 조합하여 하나의 열로 표현한다.
- Inner Join : 이너 조인(내부 조인)은 둘 이상의 테이블에 존재하는 공통 속성의 값이 같은 것을 기준으로 조인하여 결과를 추출한다.
9번 Cell) 행, 열, 항목값의 속성을 직접 설정하여 테이블을 생성한다.
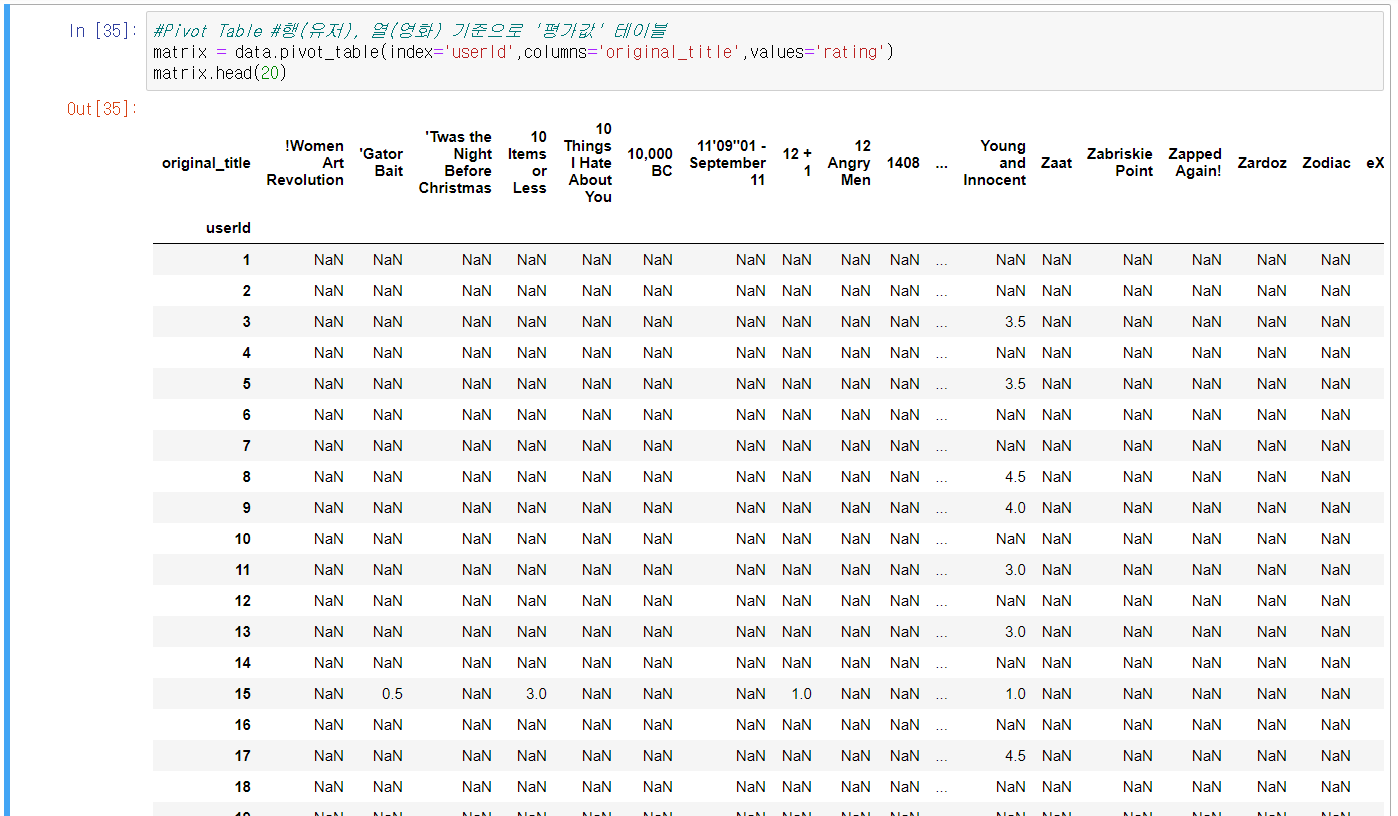
ㆍ1줄) index(행)은 userId를 기준으로, columns(열)은 original_title을 기준으로 하는 테이블을 생성. 각 항목값은 rating값이며 비어있는 항목은 NaN으로 표시된다.
10번 Cell) 우선순위를 매기기 위한 지수 추출 함수, 추천함수 생성

ㆍGENRE_WEIGHT = 0.1 : 장르가 같은 영화에 대해서 가산점을 주기 위해 설정한 가중치
ㆍdef pearsonR(s1, s2) : 입력된 영화 s1과 비교대상인 테이블 내 영화 s2간의 상관 계수를 추출하기 위한 함수.
[영화 추천 인공지능 만들기] (1) 피어슨 상관 계수에 대한 이해 (Pearson Correlation Coefficient)
파이썬 인공지능 실습을 진행중이다. 이에 선행되어야 할 피어슨 상관 관계에 대한 개념 이해를 위해 짚고 넘어가기로 한다. [개념] ㆍ피어슨 상관 계수란? - 두 변수의 상관관계를 의미하는 수
leesteady.tistory.com
ㆍdef recommend (input_movies, matrix, n, similar_genre=True)
- input_movies : 입력될 영화 제목. 가령 내가 이 영화와 비슷한 영화를 추천받고싶다 라고 말 하는 그 영화.
- matrix : 앞서 생성한 matrix
- n : 추천 받을 영화의 갯수
- similar_genre = True : 장르가 같은 영화에 가중치를 두겠다. (False일 경우는 그러지 않겠다.)
ㆍfor title in matrix.columns : matrix의 column(열)에 해당하는 영화 제목을 순서대로 's2'에 입력하겠다.
ㆍcor = pearsonR(matrix[input_movies], matrix[title]) : cor변수에 '피어슨 상관 계수'를 저장한다.
ㆍif similar_genre and len(input_genres) > 0 : similar_genre가 True이기 때문에 다음 조건문은 항상 성립한다.
ㆍnp.in1d : 입력한 영화의 장르와 같은 장르라면 (배열에 같은 요소가 있으면) True 반환.
ㆍresult.append : 결과 테이블의 형식 지정.
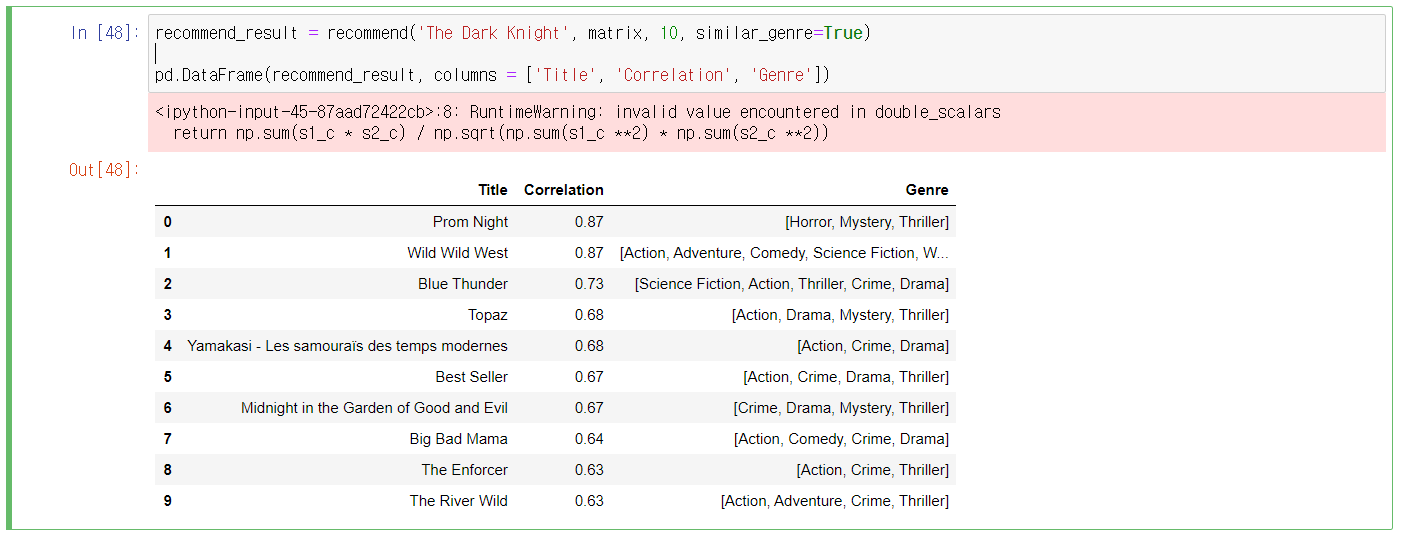
11번 Cell) 추천 시스템 정상 작동 예시
11번 Cell) 추천 시스템 작동 오류 예시
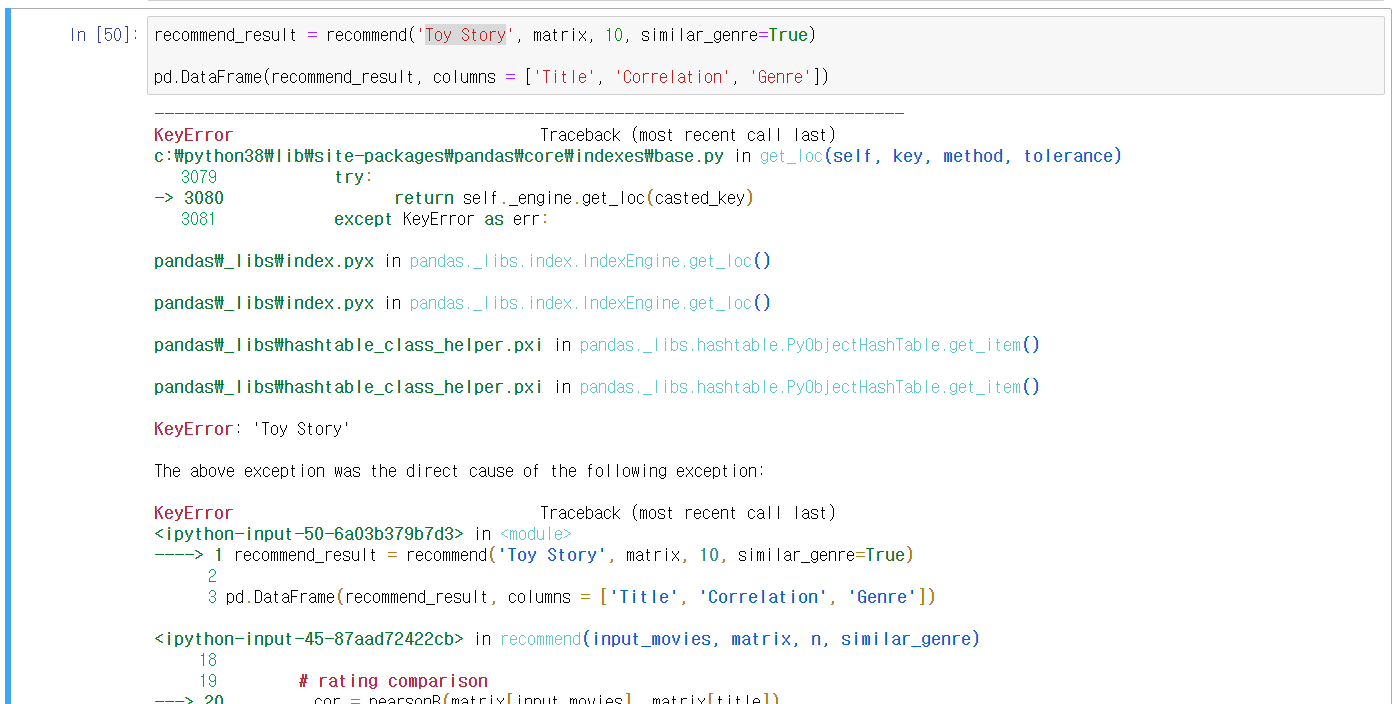
ㆍrating_small 파일에 Toy Story의 movieId인 864가 없다.
ㆍmovies_metadata와 rating_small의 csv파일에 전부 포함된 영화만 검색이 되기 때문에 에러 발생.
'컴퓨터과학' 카테고리의 다른 글
| [JAVA개념공부]is-a관계 (상속관계의 객체화) (0) | 2021.05.25 |
|---|---|
| [JAVA개념공부]메소드 오버로딩, 접근 지정자 (0) | 2021.05.24 |
| [영화 추천 인공지능 만들기] (3) 데이터 불러오기 (0) | 2021.03.25 |
| [영화 추천 인공지능 만들기] (2) Jupyter Notebook으로 환경 조성. (0) | 2021.03.24 |
| [영화 추천 인공지능 만들기] (1) 피어슨 상관 계수에 대한 이해 (Pearson Correlation Coefficient) (0) | 2021.03.24 |