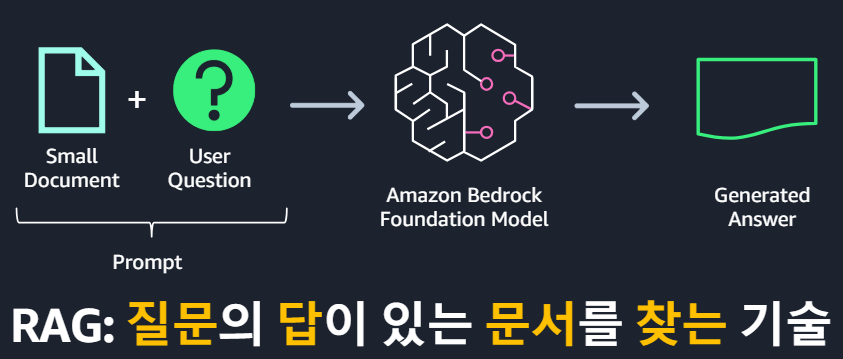
RAG는 "Retrieval-Augmented Generation"의 약자로, 텍스트 생성 모델의 성능을 향상시키기 위해 검색(retrieval) 기술을 결합한 접근 방식입니다. RAG는 크게 두 가지 주요 컴포넌트로 구성됩니다:
검색 컴포넌트 (Retrieval Component):
이 컴포넌트는 대규모 데이터베이스나 문서 집합에서 관련 정보를 검색하는 역할을 합니다.
주어진 입력 문장이나 질문에 대해 관련성이 높은 문서를 찾아냅니다.
이 과정은 보통 검색 엔진이나 특정 문서 임베딩 기법을 사용하여 이루어집니다.
생성 컴포넌트 (Generation Component):
이 컴포넌트는 검색된 정보를 바탕으로 자연스러운 텍스트를 생성합니다.
주로 트랜스포머(Transformer) 기반의 언어 모델을 사용합니다.
검색된 문서의 내용을 참고하여 질문에 대한 답변을 생성하거나 특정 주제에 대한 설명을 제공합니다.
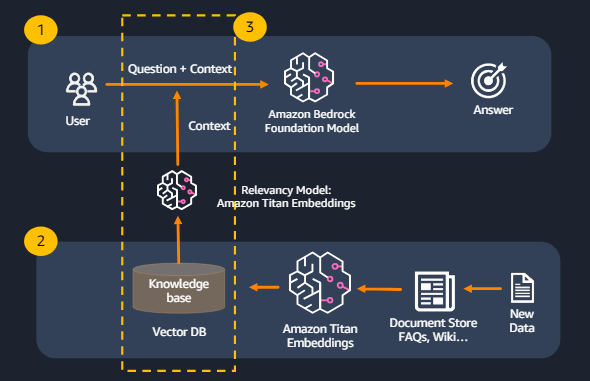
RAG의 작동 원리
입력 받기: 사용자가 질문이나 문장을 입력합니다.
정보 검색: 입력된 내용을 기반으로 검색 컴포넌트가 관련 문서를 데이터베이스에서 검색합니다.
정보 통합: 검색된 문서의 정보를 바탕으로 생성 컴포넌트가 자연스러운 텍스트를 생성합니다.
응답 제공: 최종적으로 생성된 텍스트가 사용자에게 제공됩니다.
RAG의 장점
정확성 향상: 단순한 텍스트 생성 모델에 비해, RAG는 외부 데이터를 참조하여 보다 정확하고 관련성 높은 답변을 생성할 수 있습니다.
정보 보강: 데이터베이스의 최신 정보나 전문 지식을 활용할 수 있어, 모델이 사전에 학습하지 않은 정보도 제공할 수 있습니다.
유연성: 다양한 주제나 질문에 대해 유연하게 대응할 수 있습니다.
사용 사례
질의응답 시스템: RAG는 사용자 질문에 대해 정확한 답변을 제공하는 데 유용합니다.
챗봇: 대화형 AI 시스템에서 더 자연스럽고 유익한 응답을 생성할 수 있습니다.
문서 요약: 긴 문서를 요약하거나 특정 정보를 추출하는 데 사용될 수 있습니다.
RAG는 이러한 검색과 생성의 결합을 통해 보다 풍부하고 신뢰성 높은 텍스트 생성 시스템을 구축하는 데 중요한 역할을 합니다.
(RAG의 비즈니스적 이해)
ㆍRAG
- 질의응답 X
- 정답이 포함된 문서를 찾는 기술 O
embeding : semantic의미 있는 array의 형태로 저장되는
embeding값과의 유사성이 있는 대상을 추출.
왜 실제 운영환경에서의 RAG가 유의미한 성능을 못보이는가?
1.
Context = 질문에 대한 답변 / Retrieval = 가져오다
대부분 semantic search (text의 의미의 관련성 중심) 가 중요
* semantic은 물론이고 lexical도 포함되어야함.
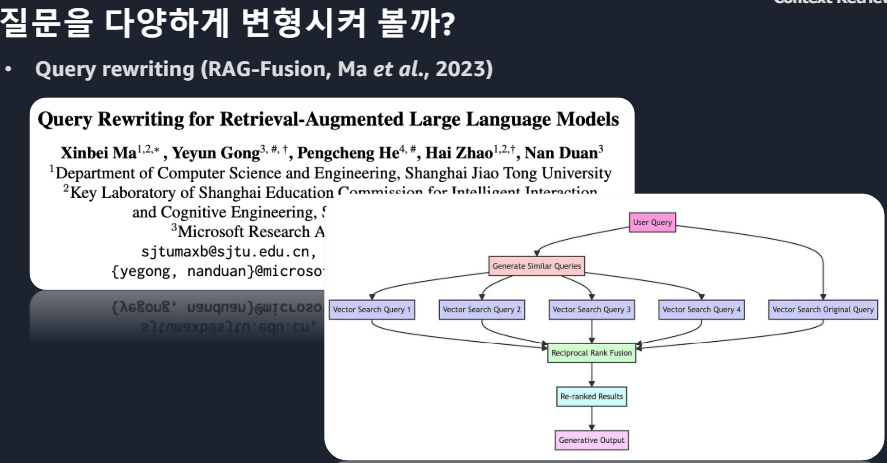
Lexical, Semantic 대표적인 Engine두 방식을 적절히 합치는 방식 (RRF)
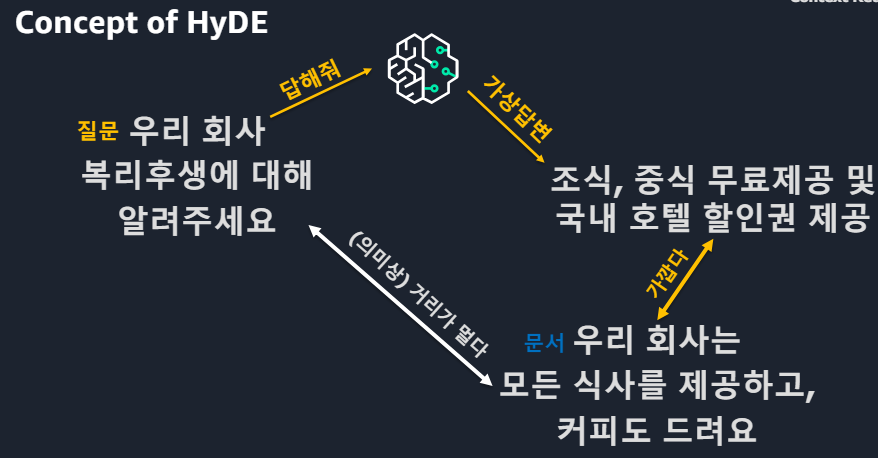
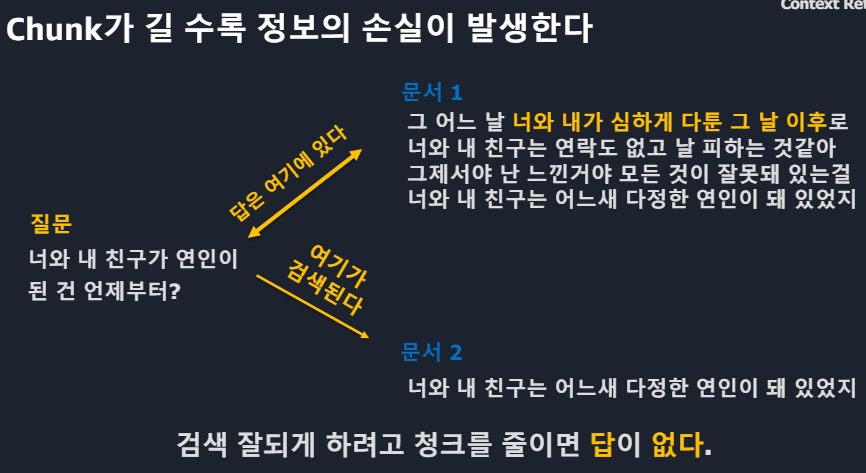
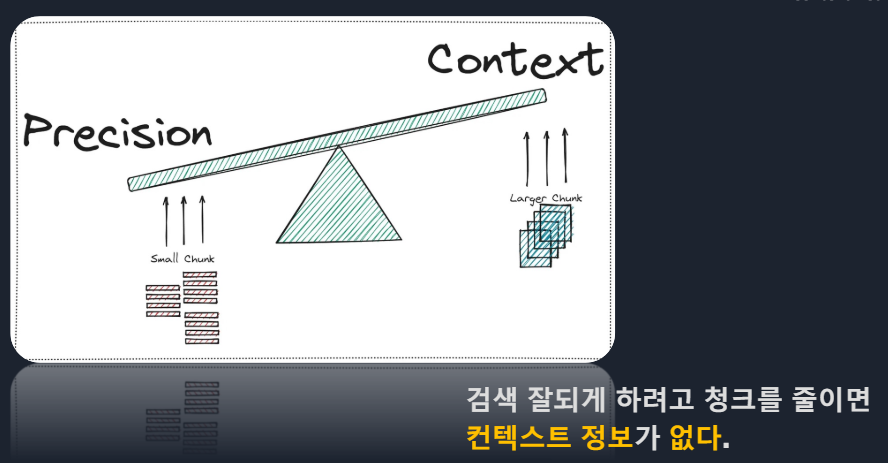
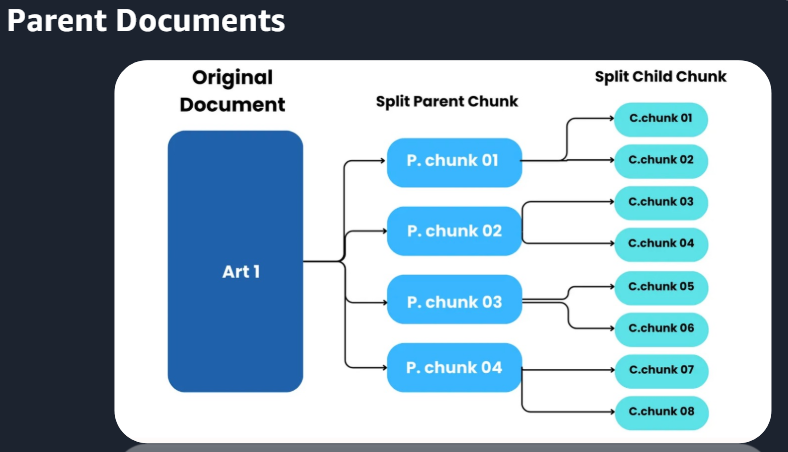
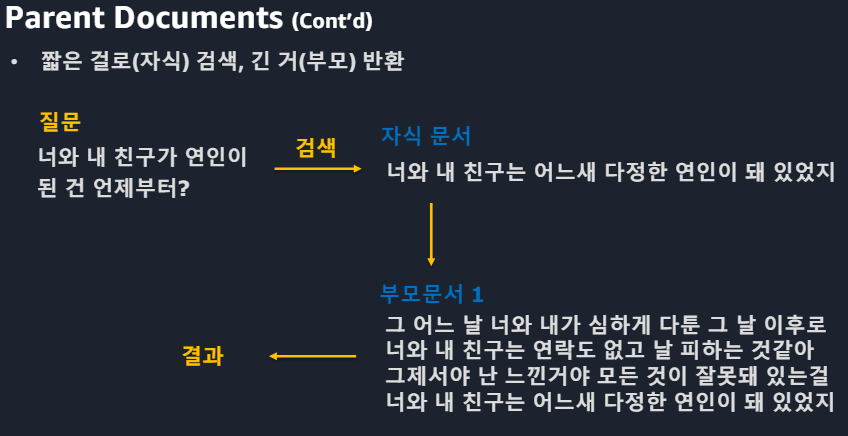
Query Rewriting 질문을 다양하게Semantic gap > RAG의 학습 의미와 질문의 의미가 유사해야 하지만 위 예시의 질문과 문서는 대답은 되지만 유사한 의미는 아니라고 볼 수 있다.HyDE방식(1)HyDE방식(2)예를들어 임베딩 결과 5개 숫자로 나타내고자 한다면 당연히 짧은 문단이 더 정확할 것.문서2는 semantic 유사성이 크다. 문서1은 semantic 유사성이 있긴 있다.질문에 대한 답을 낼 수는 있겠으나 질문의 의미가 퇴색될 수 있다.그에 대한 해답 : Parent Documents는 정답도출과 Context유지가 가능ParentDocumets 예시
필터링이 필요직접 셋팅 = 불가필터링 필드 정의 > LLM이 직접 필터링
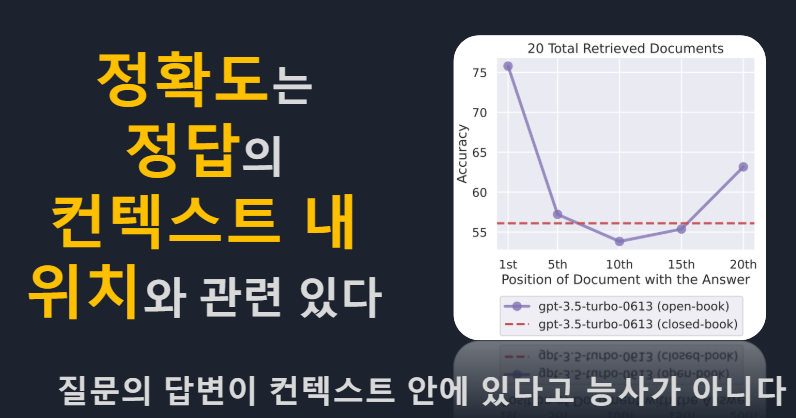
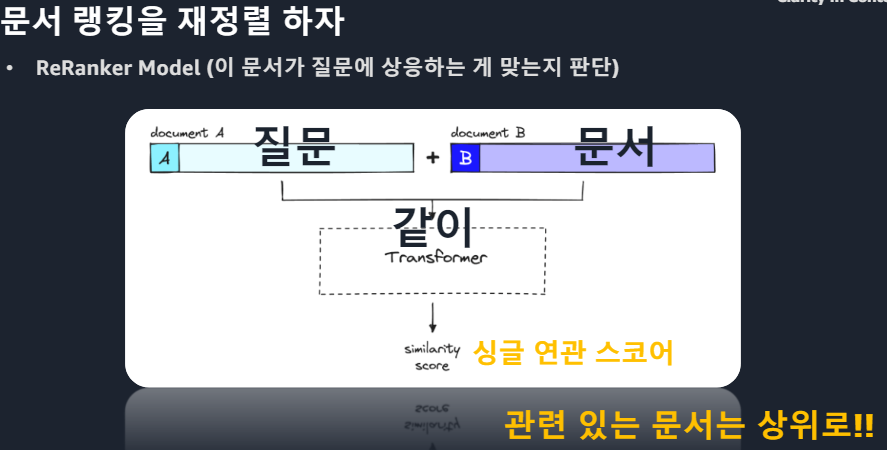
답변 정보는 컨텍스트 상위에 있어야 한다. : 문서에 포함되는 답의 위치가 중요하다. > 문서 안에서 답의 랭크가 높은 경우 > 정확도 상승
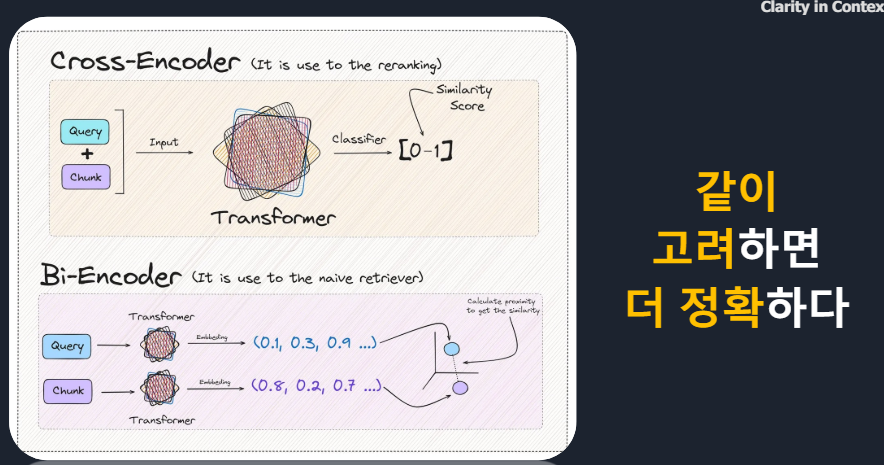
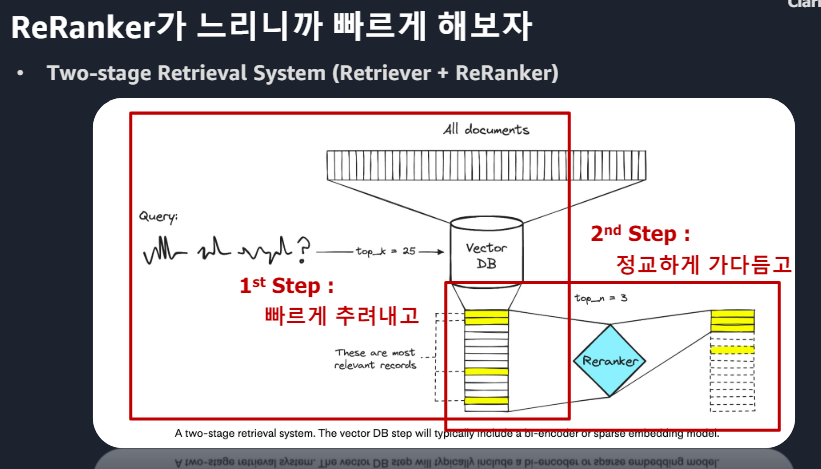
chunk하나하나 계산 다할꺼야? > 유사도 점수 정교화 상관없이 대답에 시간이 오래걸리고 힘들다 > Approximately 하게 해소Bi-Encoder : 쿼리, chunk 간 영향 X / Cross-Encider : query간, chunk간 같이 분석
*Cross-Encoder 단점 : 모든 대상을 계산해야해서 오래걸린다
* Bi-Encoder 장점 : 빠르다
public LLM은 우리에게 정확한 대답을 주지 못하지만 FineTunning은 아직!임베딩 튜닝 : 수치계산 개선 / LLM 튜닝모델을 정확히 기준을 갖고 판단해야한다정확도 100%을 바라는것 보다는 양을 늘려 다수의 정답을 도출